Naïve Bayes Assumption

조건부 독립인 관계에 있는 두 확률 변수는 해당 조건 아래선 서로에게 영향을 끼치지 않는다. 이러한 가정을 함으로써 계산량을 줄일 수 있다. 예를 들어, 이미 스팸 메일로 분류된 메일의 본문에서 Drug와 Buy는 하나의 등장이 다른 하나의 등장에 영향을 끼치지 않는다고 가정한다.
Bayes Rule
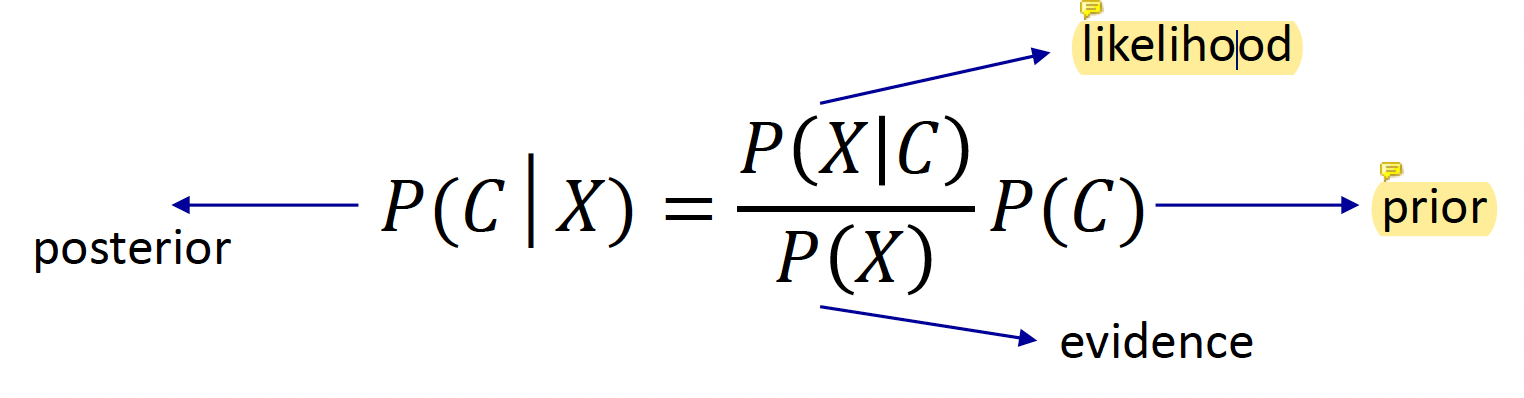
Conditional Probability에서 사용되는 중요한 공식이다. Posterior는 우리가 구하고자 하는 목표 대상이다. 주어진 조건(X)에서 분류 결과(C)일 확률을 의미한다. Likelihood는 어떠한 분류(C)에서 주어진 조건(X)을 만족할 확률이다. 이는 Naïve Bayes Assumption에 따라 계산된다. Prior는 어떠한 분류(C)의 확률이다.
예를 들어, 스팸메일 여부를 분류(yes | no)하고자 하는데 조건이 특정 단어의 등장 횟수(secret: 2, prize: 2, ...)라고 하자. 입력된 메일에서 특정 단어의 등장 횟수를 세어 조건을 형성하고, 이 메일이 스팸인지 가려내고자 한다. 스팸(yes)일 확률과 스팸이 아닐(no) 확률을 각각 구해서 더 큰 확률에 따라 분류한다. 주어진 조건의 메일이 스팸일 확률(posterior) 다음 의 곱으로 나타낸다. 먼저 스팸일 때 주어진 조건을 만족할 확률(likelihood)는 스팸일 때 조건의 각 항목을 하나씩 만족할 각각의 확률의 곱, 즉, P(secret: 2, prize: 2, ... | yes) = P(secret: 2 | yes)P(prize: 2 | yes)...으로 구할 수 있다. 그리고 조건 상관없이 스팸으로 분류될 확률(prior)이다. evidence는 구하지 않는다. 왜냐하면 스팸일 확률과 스팸이 아닐 확률 중 큰 값인 분류를 찾는 것이 목표기 때문이다.

'대학교 공부 > 기계학습' 카테고리의 다른 글
| Logistic Regression (1) | 2022.12.13 |
|---|
